library(GGally)
ggparcoord(iris, columns=1:4,
title = "Parallel coordinate plot for Iris flowers")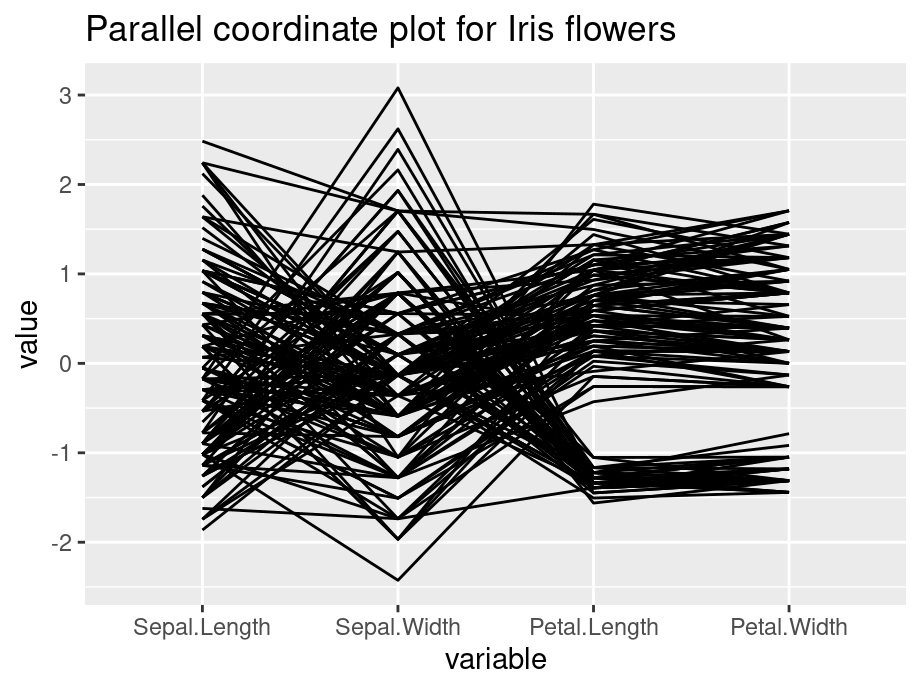
In this chapter, we will look at techniques that explore the relationships between multiple continuous variables.
For the following example, we use the famous iris data set. After installing GGally, we use ggparcoord to create the plot simply by specifying the columns we want.
library(GGally)
ggparcoord(iris, columns=1:4,
title = "Parallel coordinate plot for Iris flowers")
Generally, parallel coordinate plots are used to infer relationships between multiple continuous variables - we mostly use them to detect a general trend that our data follows, and also the specific cases that are outliers.
Please keep in mind that parallel coordinate plots are not the ideal graph to use when there are just categorical variables involved. We can include a few categorical variables for the sake of clustering, but using a lot of categorical variables results in overlapping profiles, which makes it difficult to interpret.
The default parallel coordinate plot might be messy and hard to interpret. The following techniques will help to create better visuals and convey clearer trends.
Generally, you use grouping when you want to observe a pattern by group of a categorical variable. To do this, we set groupColumn to the desired categorical variable.
In practice, parallel coordinate plots are not going to be used for very small datasets. Your data will likely have thousands and thousands of cases, and sometimes it can get very difficult to observe anything when there are many overlaps. We set the alphaLines between zero and one, and it reduces the opacity of all lines.
Sometimes the value in your variables have very different range and it is necessary to rescale them to make comparisons. By default, ggparcoord standardize your data.
The following are some other scaling options:
Generally, we use splines if we have a column where there are a lot of repeating values, which adds a lot of noise. The case lines become more and more curved when we set a higher spline factor, which removes noise and makes for easier observations of trends. It can be set using the splineFactor attribute.
You can reorder your columns in any way you want. Simply put the order in a vector. For example:
columns = c(1,3,4,2,5)Consider the following example, we apply grouping, alpha tuning, scaling and splines on the iris data set. Compare the two plot and the modified graph is noticeably easier to interpret.
ggparcoord(iris, columns=1:4, groupColumn=5, alpha=0.5, scale='uniminmax',splineFactor=10,
title = "Modified parallel coordinate plot for Iris flowers")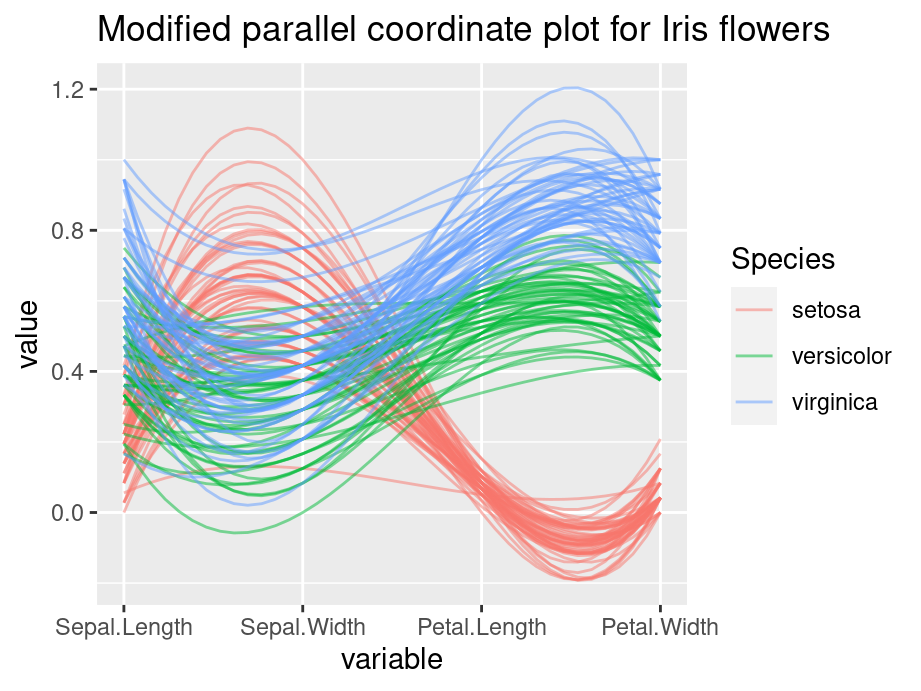
Package parcoords can help us in creating interactive parallel coordinate plots. The following example is created using New York State crime data.
widget <- df_a |>
select(-c("Year", "Months Reported", "Index Total", "Violent Total",
"Property Total")) |>
arrange(df_a) |>
parcoords(rownames = FALSE,
reorderable = TRUE,
brushMode = "1D-axes",
color = list(colorBy = "Region",
colorScale = "scaleOrdinal",
colorScheme = "schemeCategory10"),
alpha = 0.5,
width = 625, # for regular .html (not book format)
height = 650, # use fig-width and fig-height instead
withD3 = TRUE)
htmlwidgets::saveWidget(widget, "resources/pcp_widget.html",
selfcontained = TRUE)
# graph included through <iframe> in Quarto book so all interactive features
# would work; not necessary for regular .html output / reveal jsIn the interactive graph, for each feature, you can create a square box to filter for observations. For example, you can look at a certain county, or you can filter for all counties that are in New York City (Region=NYC). Overall, the interactive plot is more flexible for analysis.
Just like a static graph, there is a lot of things you can change in the interactive setting. Refer to the Introduction to parcoords vignette for more options. Unfortunately, at the time of this writing the original blog post about the library is not available.
In the following chapter, we will introduce biplot. We will talk briefly on how to create a biplot and how to interpret it.
We first introduce PCA as the existence of biplot is built up on it. Given a data set with multiple variables, the goal of PCA is to reduce dimensionality by finding a few linear combinations of the variables that capture most of the variance. Consider the following example using rating of countries.
As a common technique, we first standardize each variable to have mean of 0 and variance of 1
scaled_ratings <- ratings |>
mutate(across(where(is.numeric), ~round((.x-mean(.x))/sd(.x), 2)))
scaled_ratings# A tibble: 13 × 7
country living_standard climate food security hospitality infrastructure
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Italy 0.9 1.04 1.2 0.5 -0.34 0.83
2 Spain 0.9 1.49 1.2 0.5 -0.74 1.23
3 Croatia -0.12 0.14 -0.03 1 0.47 0.43
4 Brazil -0.12 1.04 0.38 -0.5 -0.74 -0.77
5 Russia 0.39 -1.67 -1.68 -0.5 1.27 0.43
6 Germany 1.41 -1.22 -1.68 2 1.27 1.63
7 Turkey -0.12 1.04 1.2 -0.5 -1.15 -0.77
8 Morocco -0.63 0.59 0.79 -1 -1.15 -1.17
9 Peru -0.12 0.14 -0.03 -0.5 0.06 -0.37
10 Nigeria -1.64 -0.76 -0.85 -1 -0.34 -1.17
11 France 1.41 -0.76 0.38 1.5 2.08 1.23
12 Mexico -1.64 -0.31 -0.44 -1 -0.34 -0.77
13 SouthAfrica -0.63 -0.76 -0.44 -0.5 -0.34 -0.77To apply PCA, we use function prcomp(). summary() will then be used to show result.
pca <- prcomp(ratings[,2:7], scale. = TRUE)
summary(pca)Importance of components:
PC1 PC2 PC3 PC4 PC5 PC6
Standard deviation 1.854 1.4497 0.43959 0.39052 0.27517 0.19778
Proportion of Variance 0.573 0.3503 0.03221 0.02542 0.01262 0.00652
Cumulative Proportion 0.573 0.9232 0.95544 0.98086 0.99348 1.00000As we can see that the first two principal components capture 92.3% of the total variance.
mat_round <- function(matrix, n = 3) apply(matrix, 2, function(x) round(x, n))
mat_round(pca$rotation) PC1 PC2 PC3 PC4 PC5 PC6
living_standard -0.429 0.364 0.112 -0.673 0.466 -0.028
climate 0.270 0.585 -0.210 0.036 -0.149 -0.719
food 0.221 0.596 0.610 0.212 -0.077 0.417
security -0.475 0.244 -0.282 0.676 0.419 0.049
hospitality -0.484 -0.216 0.636 0.170 -0.213 -0.490
infrastructure -0.484 0.252 -0.297 -0.121 -0.731 0.256We are also able to see the specific linear combination of variables for each principal component.
To draw a biplot, we suggest using draw_biplot from redav package. You can install the package using remotes::install_github("jtr13/redav"). Note that the function will apply PCA and draw the plot.
library(redav)
draw_biplot(ratings,arrows=FALSE)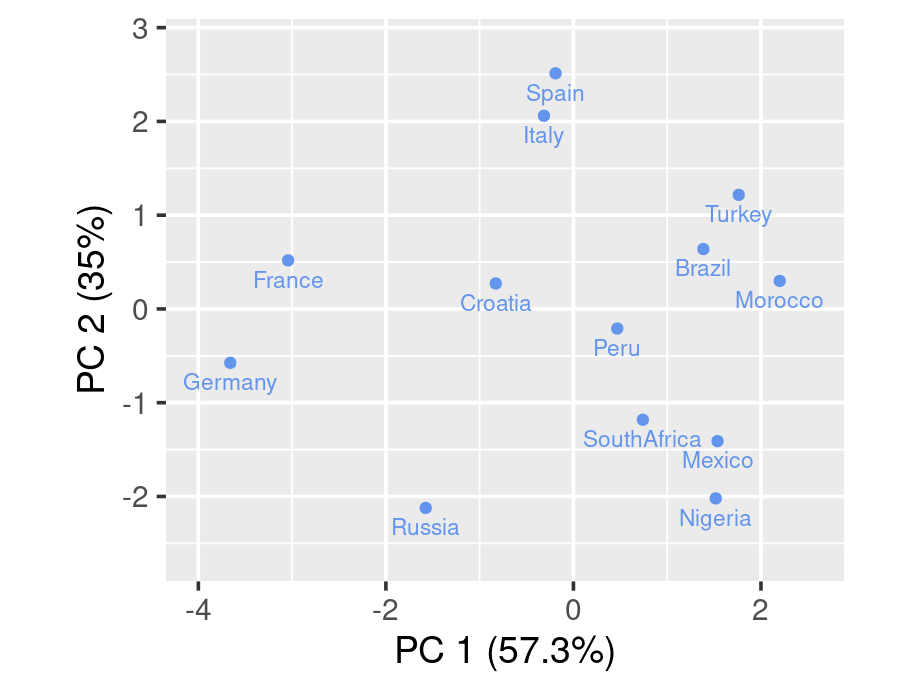
The above biplot is set to be without arrows. We can rougly identify clusters from the graph. By running some clustering algorithm like k-means, you will be able to see it clearer.
scores <- pca$x[,1:2]
k <- kmeans(scores, centers = 6)
scores <- data.frame(scores) |>
mutate(cluster = factor(k$cluster), country = ratings$country)
g4 <- ggplot(scores, aes(PC1, PC2, color = cluster, label = country)) +
geom_point() +
geom_text(nudge_y = .2) +
guides(color="none")
g4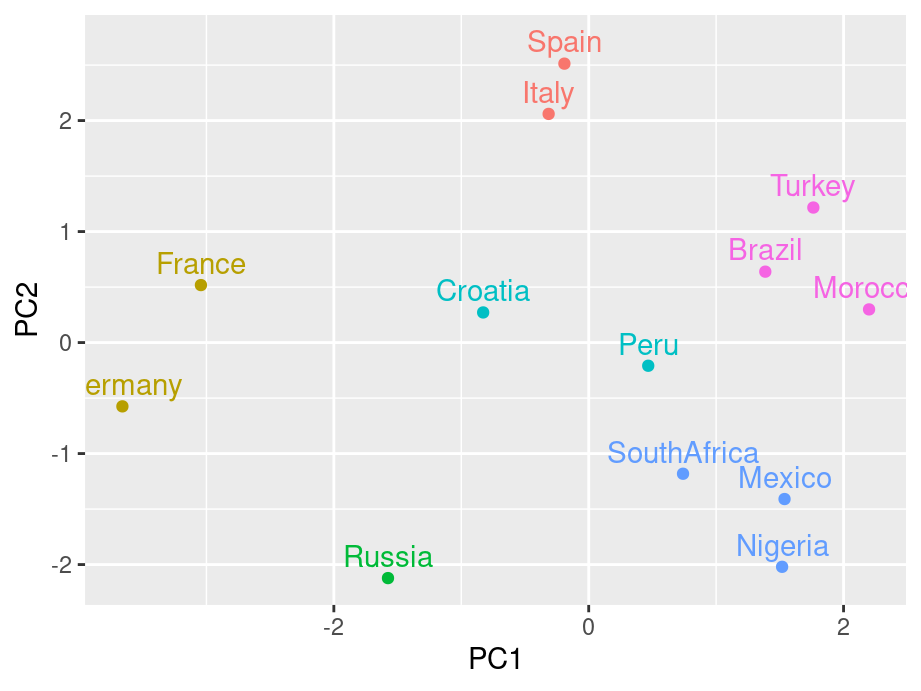
Now for a standard bibplot:
draw_biplot(ratings)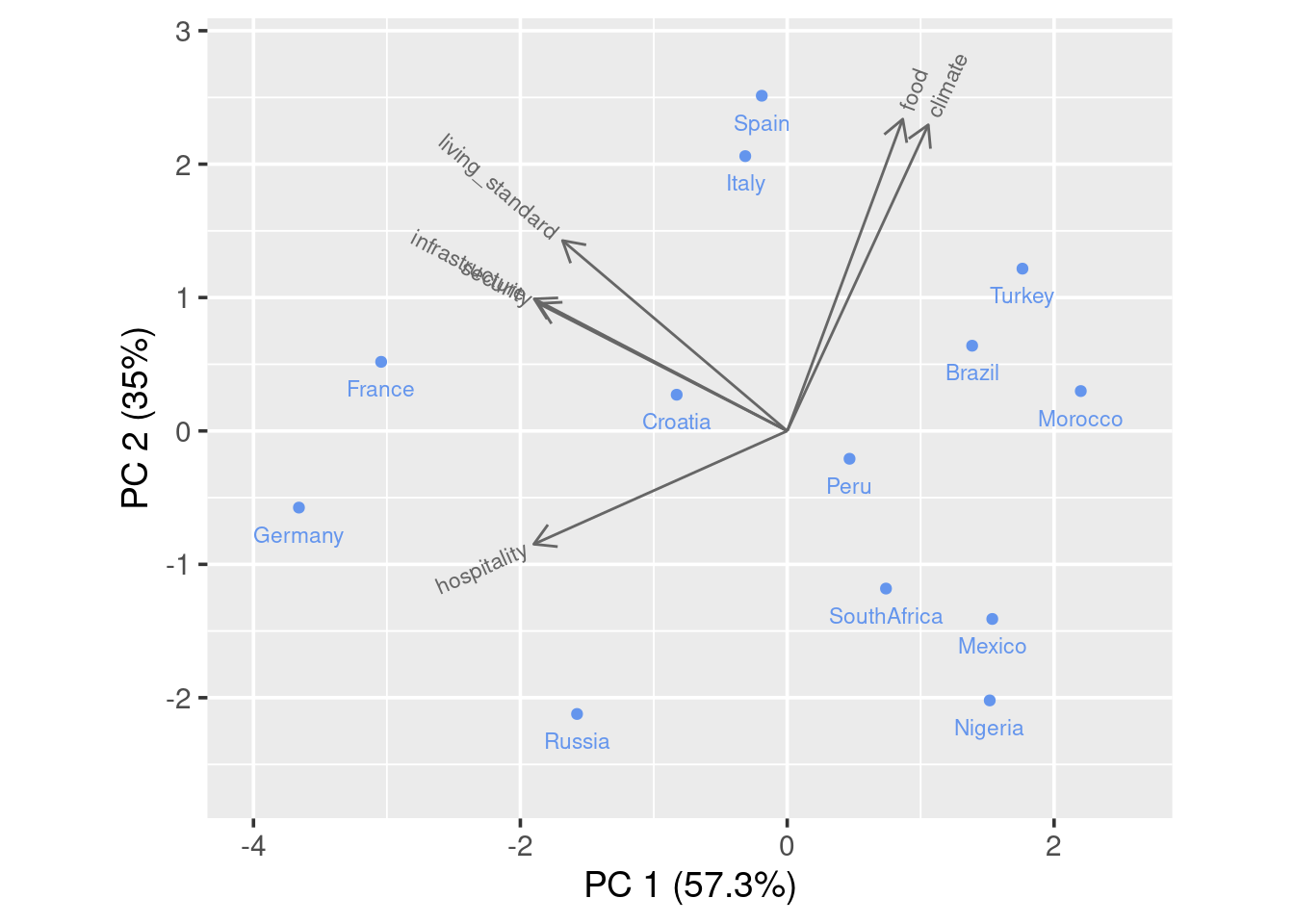
To interpret the graph, you could imagine a perpendicular line from a certain point(country) to a feature arrow you are concerned. The further the intersection is on the arrow line, the higher the score. Take Spain for example, it has high score on all variables except hospitality as the imaginary line would land on the negative axis.
You can also add calibrated axis, which will help you better compare a certain variable among countries.
draw_biplot(ratings,"living_standard")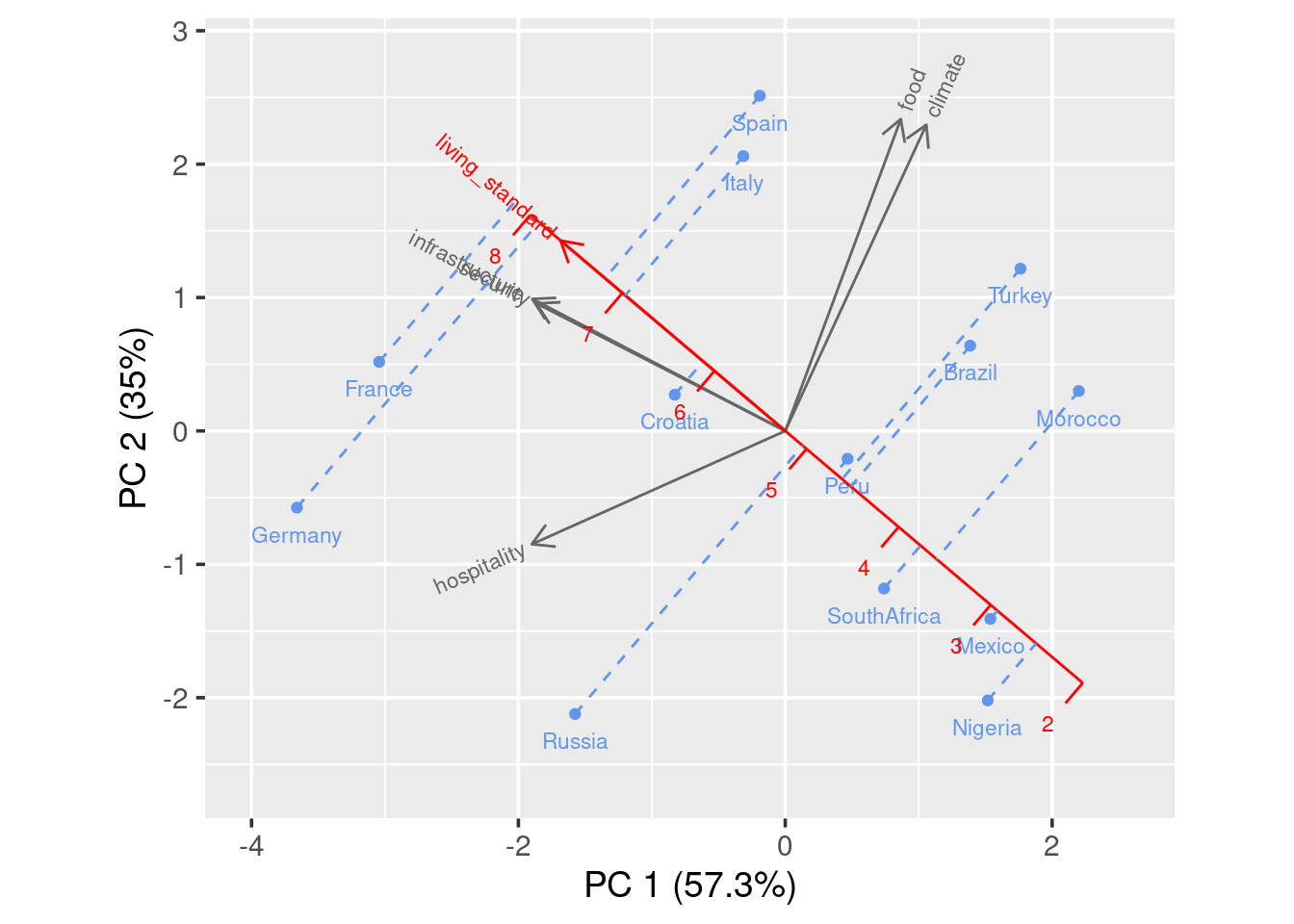
You see in this case, a projection line is added. We can clearly see that France has the highest living standard rating and Nigeria has the lowest rating.